
A data engineer is a specialist who develops data storage and processing infrastructure. They collect, organize, and transform raw data and make it ready for use by analysts or other experts.
But what skills does a data engineer need to perform their duties? At a high level, you should expect proficiency in SQL and Python, big data tools (Apache Spark, Hadoop, Hive), ETL & data pipeline (Airflow), and databases. Other important data engineer skills include experience with cloud computing, as well as streaming data processing.
In this article, you will find an overview of the most in-demand skills for data engineers found in modern job postings. By the end, you will learn the basic qualifications for most projects, the main data engineer tools, and hiring tips. So let’s get started!
Data engineer skills represent the technical and practical data engineering capabilities needed to build a robust data infrastructure. These skills cover database management, programming, cloud services, data processing frameworks, workflow automation, and security practices.
Based on current hiring demands, the fundamental data engineer skill set includes:
Also, most hiring managers look for candidates who combine technical expertise with strong personal traits, like problem-solving, independence, teamwork, and adaptability.
In this section, you’ll find out the technical part of data engineer skills that a professional should ideally have.
But keep in mind that this is a fast-moving field, and data specialists often develop deeper expertise in certain areas. In other words, while these skills should form the foundation of their knowledge, it’s rare that data engineers are experts across all these domains. Let’s take a further look!
For data engineers, SQL stands as the fundamental skill and the cornerstone of their daily work.
In fact, SQL remains one of the most used programming languages in the world, appearing in over 61.3% of skill sets of modern tech professionals. Mainly, it’s because every data project involves databases. Even some NoSQL systems now offer SQL-like interfaces because it’s so widely used.
You should look for the following SQL skills in a data engineer job description:
In addition, data engineers should know about the principles of building ETL pipelines through SQL. For example, creating stored procedures to automate data transformation processes and handling errors in batch operations.
Modern roles often require understanding both standard SQL and vendor-specific database engineer skills in platforms like PostgreSQL, MySQL, Snowflake, or BigQuery.
Now that we’ve covered data storage, let’s examine how data engineers actually manipulate and process that information with programming languages.
Previously, data engineers wrote code mainly in Java and Scala. Hadoop required Java, and Apache Spark worked better with Scala, so these languages dominated big data. Over time, data engineers began to look for simpler and faster tools.
And Python took this place thanks to its understandable syntax, huge ecosystem of libraries, and the emergence of PySpark, which opened access to Spark without Scala.
Today, most companies expect data engineers to know Python as well as SQL. Data engineers use it to create ETL processes, connect to databases and APIs, automate pipelines, and process large data sets. In fact, Python allows them to combine all parts of the modern data stack into a single coherent system.
Here are some of the most important Python skills for data engineers:
So, does data engineering need coding? Obviously, the answer is yes. The strongest data engineers combine Python libraries to build complete automated systems that move, transform, and validate data across an organization’s entire technology stack.
As companies collect more data than ever, big data engineer skills become increasingly valuable for processing massive datasets that regular systems can’t handle.
When hiring data engineering talent, prioritize hands-on experience with big data technologies:
Hiring engineers with proven big data experience means your team can immediately tackle enterprise-scale data challenges without months of training on distributed systems architecture.
Cloud computing has completely changed how companies handle data infrastructure. Data engineers now deploy pipelines on AWS, Azure, or Google Cloud instead of managing physical servers.
Each cloud provider offers specialized services that data engineers must understand. Let’s take a look.
Once you understand the foundations, it’s time to focus on what many consider the core responsibility of data engineering – ETL pipeline development.
Data engineers design workflows that pull data from source systems, transform it according to business rules, and deliver it.
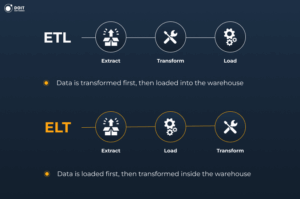
Modern data engineering increasingly uses ELT (Extract, Load, Transform) instead of traditional ETL. This approach loads raw data first, then uses the power of cloud warehouses to do transformations.
Essential data engineer tools for pipeline development include:
Also, some data engineers can work with Talend or Informatica in enterprise environments. These tools have comprehensive data integration capabilities and pre-built connectors to legacy systems that smaller tools often can’t handle.
Many businesses now need immediate insights from streaming data to stay competitive. Data engineers build systems that process events continuously, enabling real-time responses to changing conditions.
Streaming technologies handle high-speed data from IoT sensors, user actions, financial transactions, and application logs. These systems must process millions of events per second while staying fast and reliable.
Most often, you can find data engineer skills in Apache Kafka or Apache Flink for real-time streaming capabilities:
Also, data engineers can often use Apache Spark Streaming (an extension of Apache Spark for high-throughput, fault-tolerant stream processing of live data streams) or Apache Storm (a real-time computation system optimized for ultra-low latency scenarios).
Data security has become increasingly important as companies handle sensitive information under strict regulations. And your candidates should have data engineering skills to implement security measures that protect data throughout its entire lifecycle.
Security covers multiple areas. Data engineers encrypt data at rest and in transit, set up role-based access controls, maintain audit logs, and ensure compliance with regulations (for example, GDPR, HIPAA, or SOX, depending on the industry).
They also design systems that protect personal information and create secure APIs that prevent unauthorized access.
All in all, strong security practices reduce regulatory risks and protect companies from data breaches.
Now, let’s take a closer look at how data engineers ensure their systems run reliably in production without manual intervention. The basis of this process lies in DataOps, the evolution of data engineering from manual, error-prone processes to automated systems.
You should look for data engineers who can:
Good DataOps reduces operational overhead and lets teams focus on building new features instead of maintaining existing systems.
Next, let’s talk about data warehouse and lake architecture skills needed for data engineer roles.
A data warehouse works with clean, structured data that is optimized for analytics. It is an environment where business analysts and managers get quick answers through SQL queries. Examples of such systems are Snowflake, Amazon Redshift, and Google BigQuery.
A data lake performs a different function: it stores raw, often unstructured data on a massive scale. It can hold log files, images, videos, IoT data, or JSON from APIs. Amazon S3, Azure Data Lake, or Hadoop HDFS are most often used for lakes.
Modern companies often combine these two approaches in lakehouse architecture. It allows them to simultaneously store data in its raw form and make it ready for analytics without unnecessary duplication.
In this case, the data engineer builds pipelines that move data from the lake to the warehouse, or organizes a structure where both are integrated into a single environment.
To master this skill, data engineers start by working in classic warehouses and basic SQL queries. Then they learn how to manage large volumes of raw data in lakes. Next, they move on to building combined systems that meet the requirements of large-scale companies.
This development allows them to work with both clearly structured business queries and experimental data for machine learning or real-time analytics.
Finally, any artificial intelligence or machine learning algorithm depends on how well the data is prepared. The data engineer creates processes that collect data from various sources, clean it, normalize it, and convert it into a form that the model can work with.
In practice, this skill includes feature engineering.

Here, the data engineer forms new features from existing data, as well as prepares large historical datasets for training. They ensure that data is regularly updated so that models receive fresh information.
To do this, data engineers often integrate pipelines with frameworks such as TensorFlow or PyTorch, or connect data to MLOps platforms that are responsible for deploying models.
When hiring remote data engineers, finding self-motivated experts who can work independently proves essential for staying productive without constant supervision. Also, you should check their cultural awareness and the ability to work across time zones.
Want to build a strong data engineering team? Finding a data engineer with the right technical skills can be tough. While expertise in SQL, Python, big data tools, and cloud platforms is essential, don’t forget about soft skills like communication and analytical thinking.
If you’re hiring for remote positions, skills like independence and cross-cultural collaboration can determine whether your team succeeds.
The reality is that finding candidates with all the data engineer skills required takes time and technical knowledge that most hiring teams don’t have.
DOIT bridges this gap by connecting companies with vetted data engineers who have undergone comprehensive technical evaluations across all these skill areas.
If you need to hire skilled data engineers, share your project requirements and receive qualified candidate profiles within days.
Get a consultation and start building your dream team ASAP.
Request CVsData engineers need proficiency in SQL and Python programming, experience with big data technologies like Apache Spark and Hadoop, knowledge of cloud platforms (AWS, Azure, or GCP), and ETL pipeline development skills. They also require expertise in data warehousing, real-time streaming processing, and DataOps practices for production environments.
Cloud data engineers need platform-specific knowledge of services like AWS S3 and Redshift, Azure Data Factory and Synapse, or Google BigQuery and Dataflow. They must understand cloud storage options, compute scaling strategies, security configurations, and cost optimization techniques for data workloads.
Modern data engineers increasingly work with ML workflows, building feature pipelines and model serving infrastructure. While they don’t need deep ML algorithm knowledge, they should understand basic MLOps practices, feature engineering, and how to support data science teams with reliable data infrastructure.
Review their portfolio of data projects and ask for specific examples of pipelines they’ve built. Focus on their problem-solving approach, communication abilities, and experience with technologies relevant to your stack. Consider using technical assessment platforms or partnering with DOIT Software specialists who can conduct thorough technical evaluations and help hire vetted data engineers.









